- 首尾帧精准控制:首尾帧匹配度达98%,通过起始和结束画面定义视频边界,模型智能填充中间动态变化,实现场景转换和物体形态演变等效果。
- 稳定流畅视频生成:采用CLIP语义特征和交叉注意力机制,视频抖动率比同类模型降低37%,确保转场自然流畅。
- 多功能创作能力:支持中英文字幕动态嵌入、二次元/写实/奇幻等多风格生成,适应不同创作需求。
- 720p高清输出:直接生成1280×720分辨率视频,无需后处理,适用于社交媒体和商业应用。
- 开源生态支持:模型权重、代码及训练框架全面开源,支持主流AI平台部署。
- DiT架构:基于扩散模型和Diffusion Transformer架构,结合Full Attention机制优化时空依赖建模,确保视频连贯性。
- 三维因果变分编码器:Wan-VAE技术将高清画面压缩至1/128尺寸,同时保留细微动态细节,显著降低显存需求。
- 三阶段训练策略:从480P分辨率开始预训练,逐步提升至720P,通过分阶段优化平衡生成质量与计算效率。
- GitHub代码仓库:GitHub
- Hugging Face模型页:Hugging Face
- ModelScope(魔搭社区):ModelScope
Wan2.1 FLF2V 720P ComfyUI 原生工作流示例
1. 下载工作流文件及相关输入文件
请下载下面的 WebP 保存下面的 WebP 文件,并拖入 ComfyUI 中来加载对应的工作流,对应工作流已嵌入对应的模型下载文件信息。 请下载下面的两张图片,我们将会作为作为视频的起始帧和结束帧
请下载下面的两张图片,我们将会作为作为视频的起始帧和结束帧


2.手动模型安装
本篇指南涉及的所有模型你都可以在这里找到。 diffusion_models 根据你的硬件情况选择一个版本进行下载,FP8 版本对显存要求低一些 从Text encoders 选择一个版本进行下载, VAE CLIP Vision 文件保存位置3. 按步骤完成工作流运行
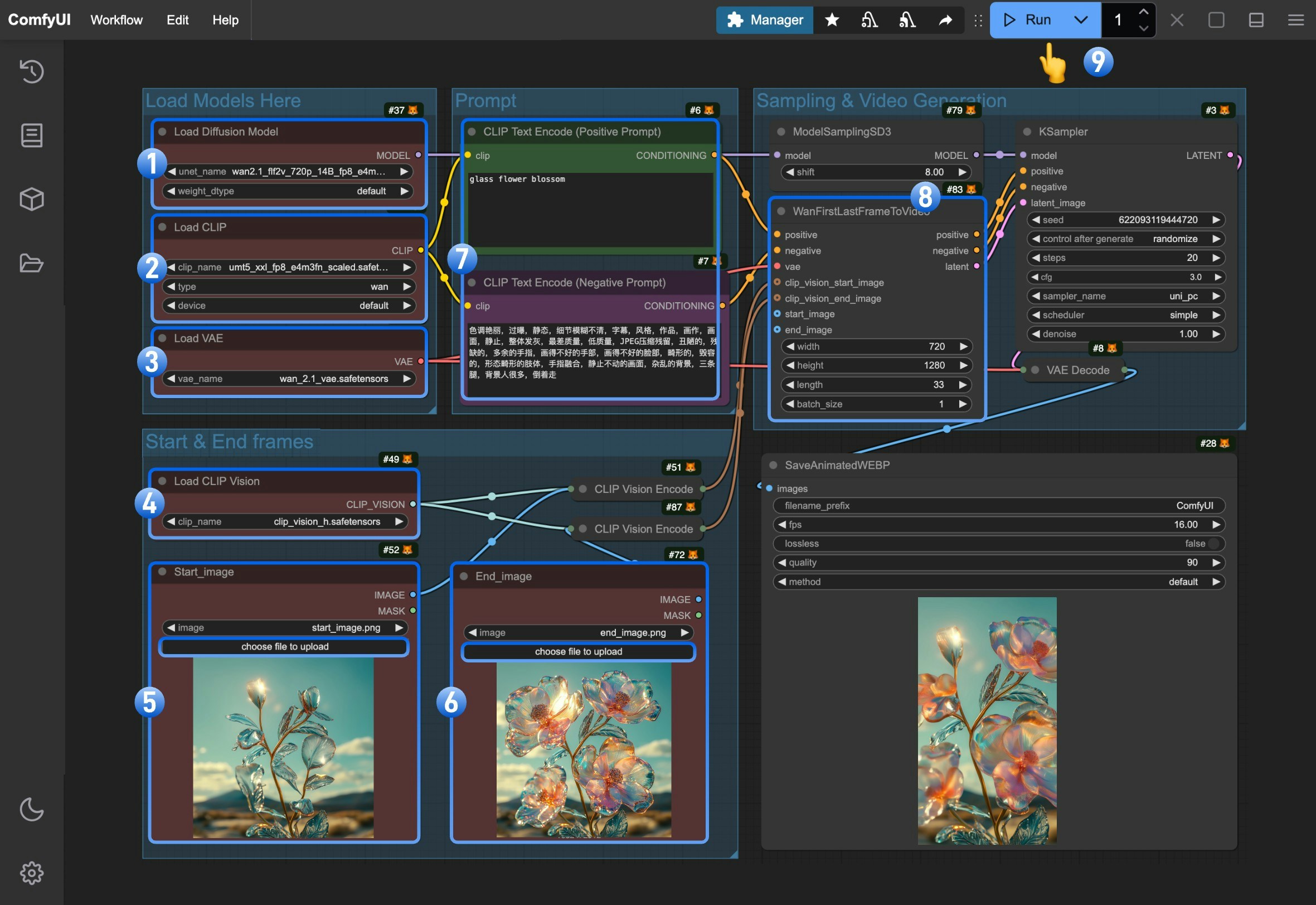
- 确保
Load Diffusion Model节点加载了wan2.1_flf2v_720p_14B_fp16.safetensors或者wan2.1_flf2v_720p_14B_fp8_e4m3fn.safetensors - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors - 确保
Load VAE节点加载了wan_2.1_vae.safetensors - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors - 在
Start_image节点上传起始帧 - 在
End_image节点上传结束帧 - (可选)修改 正向和负向的提示词(Prompt)使用中英文都可以
- (重要)在
WanFirstLastFrameToVideo修改对应视频的尺寸我们默认使用了 720 * 1280 的尺寸来,因为这是一个 720P 的尺寸来,因为这是一个720P的模型,所以使用较小的尺寸会无法获得较好的结果。 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成